
Sometimes system flexibility makes the solution complicated 😉 . Imagine a ‘simple’ situation that you have a system in which a client can define new attribute and assign multiple values to it. Later, the client can assign these values to the Customers. If you do not plan to develop new attributes’ set every time a client wants to make a change, you will need to prepare a ‘dynamic’ structure in the database. Structure can be represented in the dataset as shown in the diagram below.

Challenge
Let’s assume that your client asked you to add a new feature – marketing campaign. Business wants to filter groups of Customers by multiple attributes’ values selected from UI. Set of Customers is large – let’s say one million Customers. Each Customer has been assigned about one hundred attributes’ values. Let’s say the marketing campaign will use three attributes’ values – e.g. give me all students living in Europe with ‘married’ status. The goal is to write SQL query to handle such multi-choice – to present results on UI fast. The first solution we can propose is to build a dynamic query with multiple joins by CustomerId. Such a query can look like this.
SELECT cav1.CustomerId FROM [dbo].[CustomerAttributeValue] cav1 INNER JOIN [dbo].[CustomerAttributeValue] cav2 ON cav1.CustomerId=cav2.CustomerId INNER JOIN [dbo].[CustomerAttributeValue] cav3 ON cav1.CustomerId=cav3.CustomerId WHERE cav1.AttributeValueId=1 AND cav2.AttributeValueId=2 AND cav3.AttributeValueId=3 GROUP BY cav1.CustomerId
This solution looks rather complicated. SQL query will be generated at application level. Each new attribute value will create new JOIN. Query engine needs to work hard too. The database will have to do a lot of seeks in indexes. Each attribute value is an extra seek. Then, all returned Customers have to be joined. See the execution plan.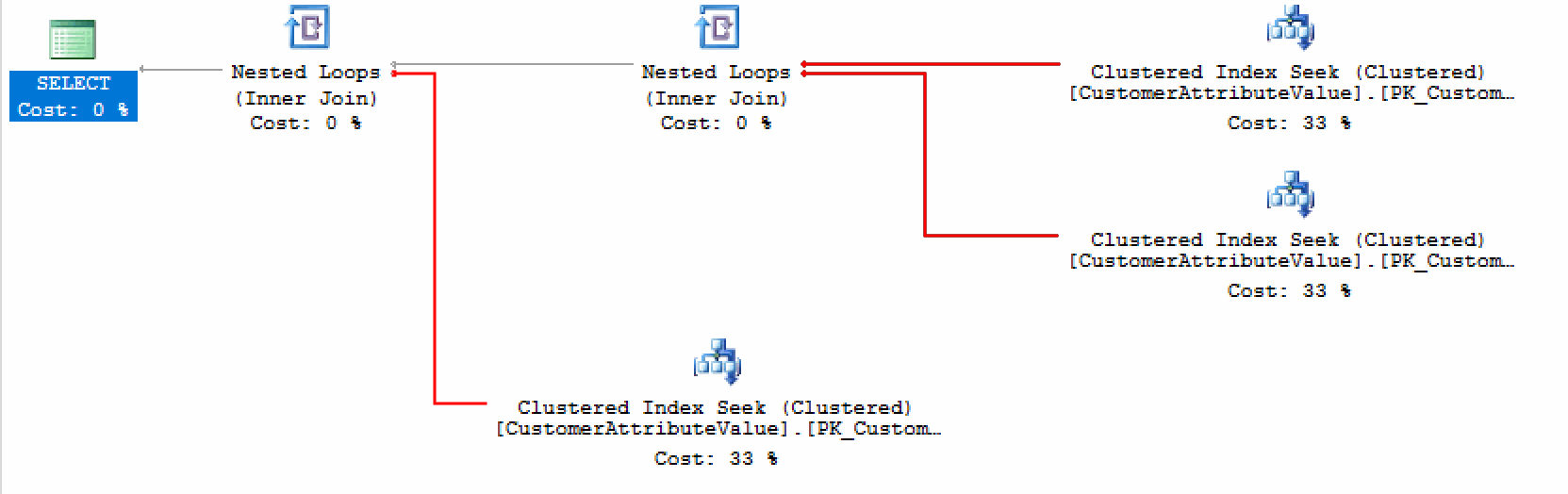 These red branches do not look well.
These red branches do not look well.
My solution
The trick I want to share with you is to use HAVING instead of JOIN. If you want to filter out Customers with specific Y attributes values, you should expect Customers times Y records for those Customers who belong to a defined set. What does it mean? When you group results by CustomerId, you should be interested only in those Customers who have exactly Y count of records in returned set. The database query can look as follows:
DECLARE @TmpAttributeValue TABLE ( [Id] INT NOT NULL ) DECLARE @RecordsCount INT INSERT INTO @TmpAttributeValue SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 SELECT @RecordsCount=COUNT(1) FROM @TmpAttributeValue SELECT cav.CustomerId FROM [dbo].[CustomerAttributeValue] cav INNER JOIN @TmpAttributeValue tav ON tav.Id=cav.AttributeValueId GROUP BY cav.CustomerId HAVING COUNT(cav.CustomerId)=@RecordsCount
The @TmpAttributeValue can be an array parameter given to stored procedure. You have only single Index Seek, so your huge CustomerAttributeValue table with about 100 million records is sought once.

Sort in the execution plan can look a little scary. But the truth is that if the CustomerAttributeValue table is already sorted by AttributeValueId then by CustomerId, filtered out records are already sorted. I have tested this solution at production and the database returned records in milliseconds.
Remember that this action is executed by super user, so it is not called too often. But if you can make their live easier by a simple trick, why not to do this 😉