
Big companies have huge internal structures. The problem they have is that huge structures have to be mapped into a permission model. One company I worked for had over 300k groups in Active Directory. As worldwide organization they have multiple domains in AD forest. Of course, various groups have various memberships so the structure was really complicated. When you need to resolve user membership in order to verify user permission your software needs to retrieve a lot of data from domain zones. PrincipalContext delivered with .NET framework is not a solution here. Test results were not really satisfactory. An average time required for user groups resolving comes around 2 minutes. Can you imagine a user waiting two minutes after submitting logon data? I cannot. I never wanted to have unsatisfied clients.
First solution I have found was described on Stack Overflow. It was simple. Each user account has been assigned an array of something called SID (Security Identifier). This property contains a set of all resolved security groups assigned to a logged on user. This solution is fast when you ask about groups using SID and AD query. Resolving SID property is a little bit slow. For super users assigned to many groups, that property works really slow. It could take over 8 to 10 seconds on the client side. It sounds better than 2 minutes, but the user experience is still far from acceptable. The second problem is that SID works well, but only with security groups. Sometimes AD contains other types of groups, not listed by SID, and that disqualifies this solution. Just for clarification – the memberOf property is auto-calculated, and it works slowly too.
Solution
The question is then: how to create a fast groups resolver for complicated AD structures? The answer to this question requires a combination of a few solutions.
Use AD property member to filter out all groups containing the specific group/user as a member. Create ‘reactive stream’ which resolves next groups subset. This resolver will create in memory dependency graph. But the truth is that this dependency graph does not have to be fully recreated. You only need a set of groups as a result. So the only thing you have to care about is not to ask for a group you have already asked. Round trip costs you too, so you need to be smart in asking for new groups. The member property uses distinguished names, so you need to ask each resolved group for the dn property.
Groups in the organization I worked for were split between a few Domains. Sometimes group memberships were mixed between Domains, so rebuilding group memberships of a user might be complicated. When we look into an algorithm it looks easy.
- Ask all Domain Zones for groups of which User is a member.
- Add each retrieved group to the pending queue, only if it has not been handled yet.
- For each pending group ask all Domain Zones for groups where Group is a member. Repeat step 2 until pending queue becomes empty.
To avoid re-handling of the same group, you can use some HashSet to avoid duplicates. Pending groups should be assigned to pending queues of each Domain Zone. This broadcast messaging simplifies AD query engine. The full query system is presented in the following picture.

Where:
- Query result Coordinator takes each found group (DN) and if DN was not handled ads it into All found groups DNs and adds it into AD Query Engines queues (broadcast).
- AD Query Engine takes from pending queue DNs (predefined batch) and asks assigned Active Directory Zone for all groups where member contains specified members.
The last thing we have to design is when to stop all the processes. We have multiple independent workers, so we have to recognize, when the entire work is done. AD Query Engines are independent, so Query Result Coordinator should be responsible for mediation. Coordinator cannot base on groups returned by search mechanism only, because number of returned groups is not correlated with pending groups count. We have to realize when all AD Query Engines finished their work. To achieve this we need feedback on the pending DNs count handled.
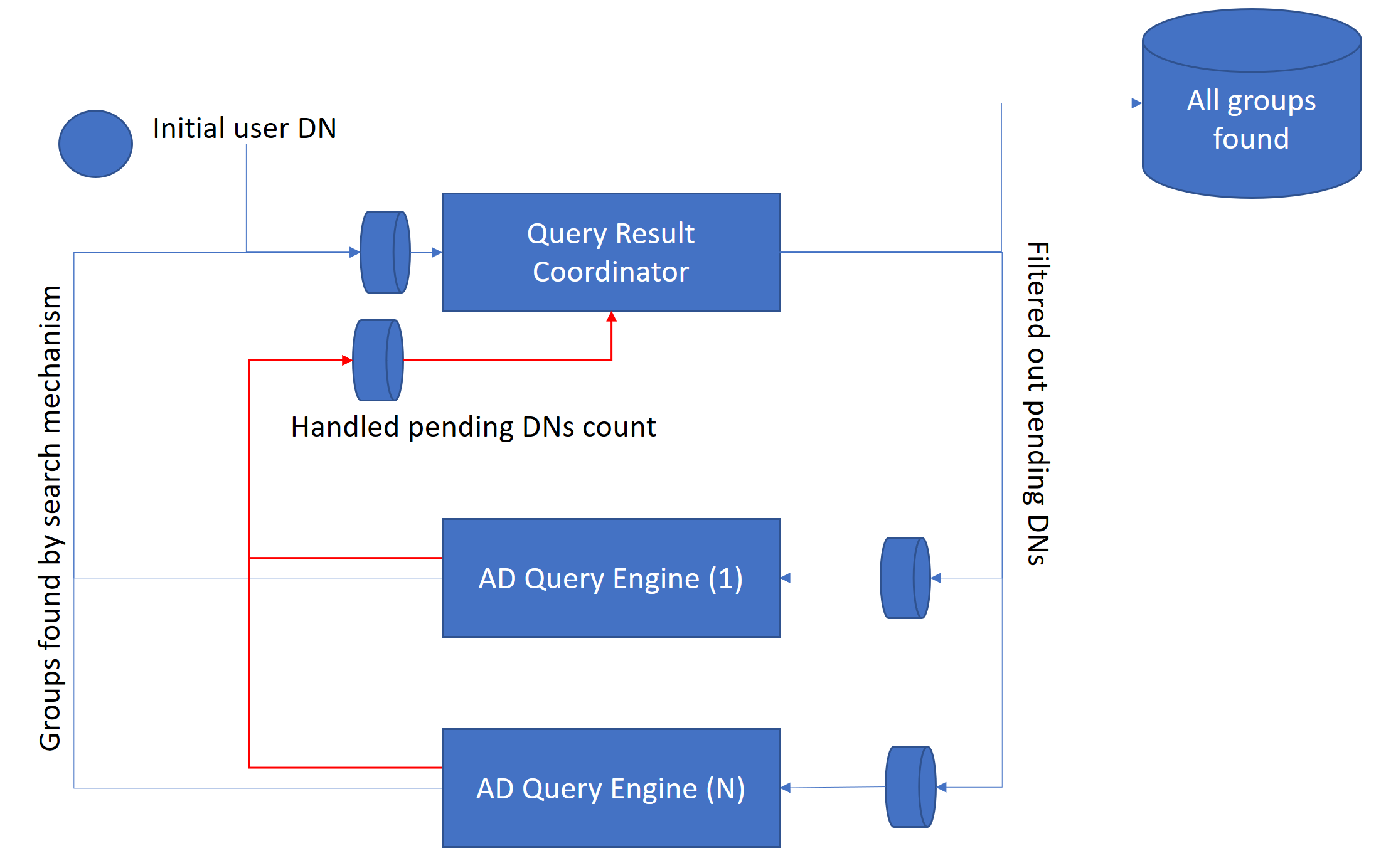
When we put e.g. 10 DNs to the pending DNs queue and each AD Query Engine reports that it handled all 10, we can stop work. But of course in the meantime new search results can appear so pending queue can receive new items to handle. As a result, we have two ‘competing’ counters: the first is increasing the pending items, the second is increasing the handled items. When they become equal, our search is finished. NOTE: Remember to increase pending items count by filtered out DNs times AD Query Engine Count.
There could be a race condition. To avoid it, you have to remember to first handle ‘search result’ and then ‘handled pending count’. So increment pending items count, is more important than increment handled items count. It can be guaranteed by AD Query Engine which should first return found groups, and then report handled items count. Handled items count can be reported even later – when last item is returned by AD Search engine and pending input queue is empty. This means that AD Query Engine finished all the current work. It allows to reduce number of synchronization points.
Now when we know how to realize this fast query engine at a high level we can see the code sample doing this job. NOTE: AD access is a mock, but you can easily replace it with AD query implementation.
Of course, there is a lot of room for improvement. One good example is to split pending DNs queue assigned to one DC Zone and do a query in pipes. So single AD Query Engine becomes multithreaded job handler. This also allows to speed up AD query.
Summary
Fast retrieval of group assignment is not a simple task. By combining knowledge of few techniques, you can create a really fast group resolver. I hope this code sample would allow you to make a faster application in Windows Active Directory when the forest is large. Maybe this solution would make you think differently about other problems you might encounter.