
Distributed Transaction Coordination is sometimes slow, but guarantees the system consistency. You do not need to care about infrastructure things. I will describe a problem that appears when you have no DTC and you have two independent databases.
The case
Let’s analyze the following scenario. You have Front End system writing into one database and Back End system with an own database. Back End uses its own database to manage workflow state and Front End database to read and write business data. Both systems realize some business workflow. High level scenario is like this:
- User sends Order
TRANSACTION STARTS - Front End starts workflow on Back End giving Order metadata for Back End
- When workflow is started Front End stores its ID in own database
TRANSACTION IS COMMITTED
This is how it looks like from business perspective. Now look on the timeline to see how the transaction was realized on Front End and Back End side.

Diagram Legend
- User sends Order
- FE saves user Order. ID is generated by the database.
- FE gets the generated Order ID and sends it to Back End.
- BE creates Workflow structure. Database generates Workflow ID.
- FE associates Workflow ID with FE Order ID.
- BE takes Workflow ID ans sends it to FE.
- FE assigns workflow ID to user Order stored in FE.
If you are familiar with distributed systems, you know that this way of implementation is not safe. It works when there are no errors 😉 . If error appears before the first commit, it is not a problem. Both transactions are rolled back and the system is consistent. But the “magic” starts when error appears after first commit when second operation is not committed.

Other system (with committed transaction) contains phantoms. The problem is that while retrying operation, new records not consistent with the previous one will be created.
So what is the solution for that problem? It depends 🙂 . The best solution in this case is to have a single database or to use DTC. But what to do if the infrastructure change is not possible – when current architecture is already approved? It could sound strange, but we have to introduce durable messaging system or custom two phase commit system.
Custom Two Phase Commit
Let’s start from two phase commit. Our custom two phase commit system means that we have to organize transactions on the business level. How can we develop it for this specific problem? The high level description looks like this.
- Generate TransactionID and store it in e.g. Back End DB. Commit DB transaction marking TransactionID as opened.
- Open now DB transactions on Back/Front End and apply to them the newly created TransactionID.
- Commit transaction on Back End.
- Mark TransactionID for Back End as committed.
- Commit transaction on Front End.
- Mark TransactionID for Front End as committed.
It is explained in the following diagram in more detail:
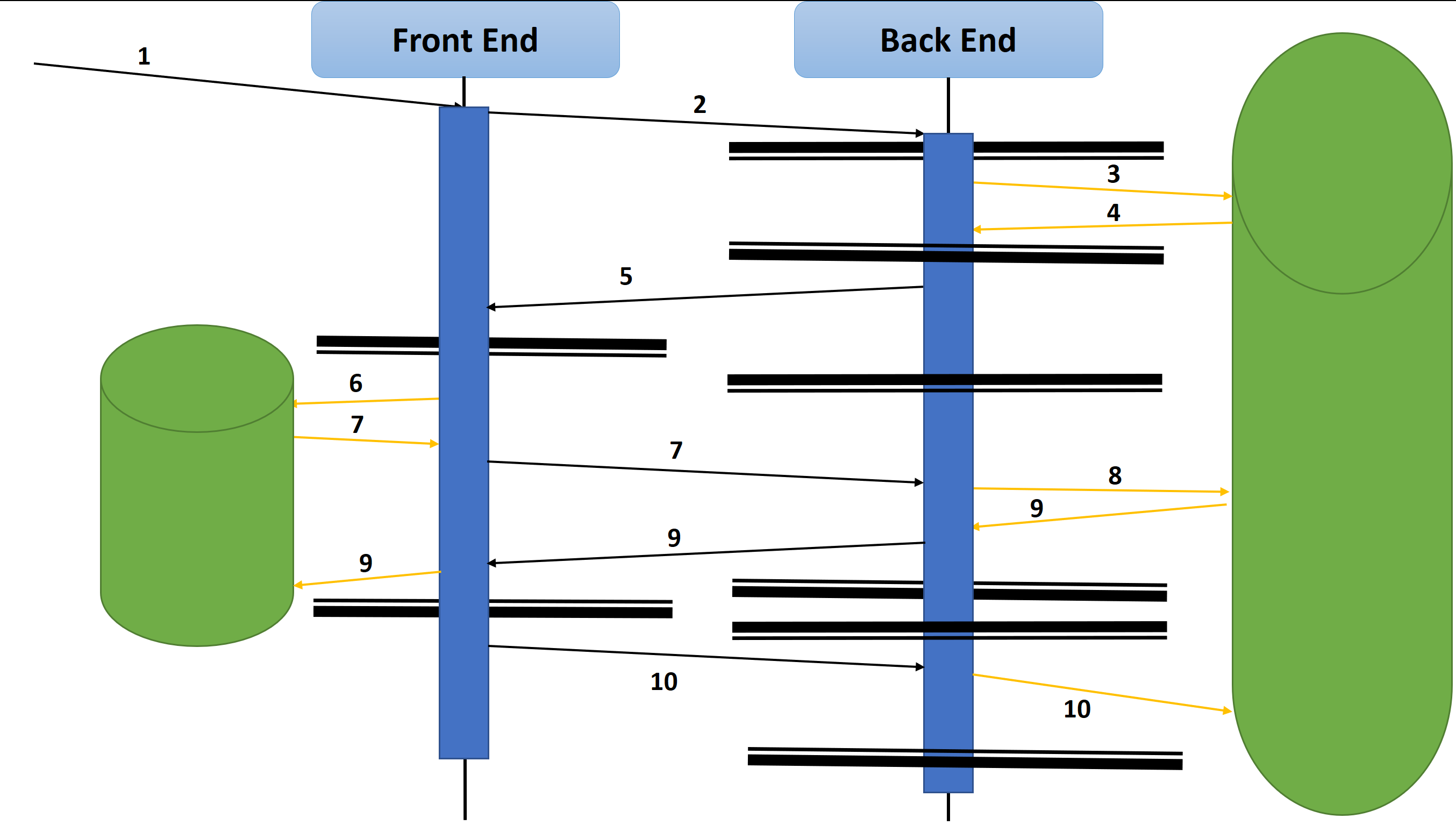
Diagram Legend
- User sends Order.
- FE informs BE that new TransactionID is required.
- BE Creates new TransactionID as not committed for BE and FE.
- BE gets TransactionID.
- BE sends TransactionID to FE.
- FE saves User Order and associates it with TransactionID.
- FE gets stored Order ID and TransactionID and sends it to Back End.
- BE database creates Workflow ID. BE associates it with stored User Order ID and TransactionID. BE marks TransactionID as committed for Back End. NOTE: Until physical database transaction commit occurs this change is not applied.
- BE gets Workflow ID and commits transaction. FE side associates User Order ID with Workflow ID and commits transaction.
- FE informs BE that transaction is committed. BE updates TransactionID with new commit status.
Until TransactionID is not marked as committed by both sides it should not be touched. If TransactionID is not committed by long time (timeout), you can clean up Front End and Back End entries and mark TransactionID as rolled back or remove it. It means that you have to create simple garbage collector process in case of failure. The situation is simpler because all records are associated with your TransactionID. Remember, that from business perspective records marked with that specific TransactionID are invalid until logical commit. So either Front End or Back End should not process them before logical commit.
Pseudo messaging system
This solution is more complicated. It also splits business tasks into few independent transactions. What is required here is not a simple structure with TransactionID, but a structure for messages. This structure requires an implementation of two independent queuing systems in both databases. What becomes simpler is that business sub-transaction is realized on a single database. It means it is consistent from an ACID point of view. What you have to handle is the exchange of messages between the databases. You have to implement your own store and forward mechanism.
Let’s first focus on sub-transaction. Scenario from the technical point of view could be:
- START TRANSACTION
- Take message from input queue (take message from local database).
- Process data and store state in DB.
- Send message (store message in local database as outgoing).
- COMMIT TRANSACTION
Database guarantees consistency so we are fine. What we have to develop now is the store and forward mechanism. In the simplest scenario you are just taking a message from Output Queue and inserting it into Input Queue of the second database, but omitting duplicates. Next you are removing the sent message from your local queue. If something fails, you have to retry this process. Because you are omitting duplicates you are safe.
At first sight this solution looks more complicated. The truth is that the framework is more complicated, but sub-transactions become easier to manage and they simplify your business logic management. And do not worry about performance. You do not need to forward messages one by one. If your outgoing queue has more messages, you can use mechanism like bulk insert to handle huge data amount.
Summary
Both solutions are only examples of how to handle problems when you have legacy system with a bug that I described.
For greenfield projects I highly recommend to use platforms that solve such problems for you. You can focus on business logic instead of solving infrastructure problems. This is why I am nostalgic about the past times when I was using NServiceBus platform.